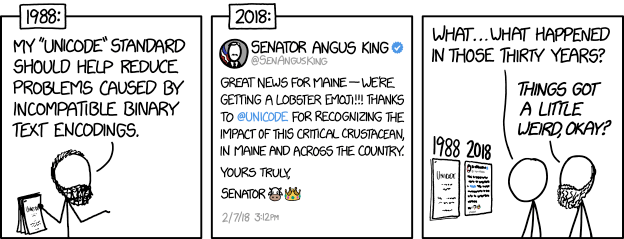
De Rechtbank Rotterdam heeft AI ingezet als schrijfhulp bij het opstellen van het strafvonnis, las ik bij Tweakers. AI is niet gebruikt om te helpen met het nemen van de rechterlijke beslissingen zelf, voegt de rechtbank daar snel aan toe, hoewel men wel enthousiast is over de resultaten. Het zette me aan het denken: wat zouden we nog meer kunnen doen met AI zonder gelijk te vallen over de bekende risico’s?
Procedureel was deze proef goed ingericht. Er is gelet op vertrouwelijkheid en integriteit, geen privacygevoelige gegevens of herleidbare feiten ingevoerd en het ging alleen om een schrijfhulp:
De suggesties en formuleringen die door de AI voor de strafmotivering zijn aangedragen op grond van ingevoerde korte algemene feiten en omstandigheden van de zaak zijn zorgvuldig beoordeeld en geselecteerd door de strafrechters en de griffier. Zij hebben daarbij gewerkt volgens de standaard werkwijze, waarin de griffier een concept maakt dat vervolgens door de strafrechters gezamenlijk is aangepast tot de definitieve strafmotivering. Van groot belang is daarbij dat AI geen beslissingen heeft genomen, beslissingen heeft voorbereid en/of afwegingen heeft gemaakt.
Hier kun je moeilijk op tegen zijn, maar de toegevoegde waarde is dan ook weer niet heel denderend. Maar we zijn nog lang niet klaar voor een robotrechter (hoi eCourt), nog los van dat die dan alle hoogrisico-eisen onder de AI Act over zich heen krijgt.
Vonnissen schrijven is voor een deel het hanteren van standaardteksten. Rechtspraak is vrij formalistisch in hoe een vonnis wordt opgebouwd, maar ook hoe je dingen motiveert. Je ziet bij zaken vaak standaardformuleringen om vaste jurisprudentie aan te halen. Een bekende is
Bij een botsing tussen enerzijds het door artikel 7 Grondwet (Gw) en artikel 10 van het Europees verdrag tot bescherming van de rechten van de mens en de fundamentele vrijheden (EVRM) gewaarborgde recht op vrijheid van meningsuiting en anderzijds het door artikel 10 Gw en artikel 8 EVRM beschermde recht op eerbiediging van de persoonlijke levenssfeer – waaronder het door haar ingeroepen recht op bescherming van de goede naam/reputatie is begrepen (EHRM 15 november 2007, no. 12556/03, Pfeifer/Oostenrijk, EHRC 2008, 6) – moet het antwoord op de vraag welk van deze beide rechten in het concrete geval zwaarder weegt, worden gevonden door een afweging van alle terzake dienende omstandigheden van het geval.
Daarna moet je al snel de jurisprudentie toesnijden op de zaak. En dat moet op een bepaalde manier, want als je niet de subsidiariteit expliciet benoemt dan kan een partij daarover piepen in hoger beroep. Daar kun je dan een sjabloon voor gebruiken, maar dat komt de leesbaarheid niet ten goede. Een LLM dat je teksten op maat schrijft vanaf jouw sjabloon is dan volgens mij een prima manier.
In de jaren negentig is geprobeerd of we niet met eenvoudiger taal kunnen procederen. Dat is in 1996 keihard afgewezen door de Hoge Raad (Klare Taal I arrest). Je moet álle wettelijke componenten noemen en wel precies met de naam uit de wet, anders weet de verdachte niet waarop hij wordt veroordeeld. In deze dagvaarding stond “Hij heeft op 8 juli 1993 in [plek] de ruiten “van de voordeur van [betrokkene] vernield”.
ChatGPT zou het ook zo zeggen. Maar dan is niet duidelijk of je bedoelt per ongeluk of opzettelijk, of hij dat mocht of niet, enzovoorts. In de ‘oude’ tenlastenlegging staat dat wel allemaal. En natuurlijk, je kunt dat er dan even bij zetten maar dan vervang je alleen “opzettelijk en wederrechtelijk” door “niet per ongeluk en zonder dat het mocht”. Dat schiet dan weinig op.
Jurisprudentie en artikelen samenvatten en als basis gebruiken? Het kan, hoewel eigenlijk de partijen natuurlijk de onderbouwing voor hun stellingen aan moeten dragen. Ik experimenteer nu met diverse “deep research” tools (zoals Perplexity en Elicit), maar ben nog niet echt tevreden over de diepgang van de resultaten. Een blog van een advocaat is niet hetzelfde als een paper in een tijdschrift.
Arnoud